Hydra: Multi-Objective Code Optimization
Most tools that make code faster only optimize for one thing (usually speed). Hydra teaches an AI model to balance speed, memory, and energy use together, the way a real engineer would.
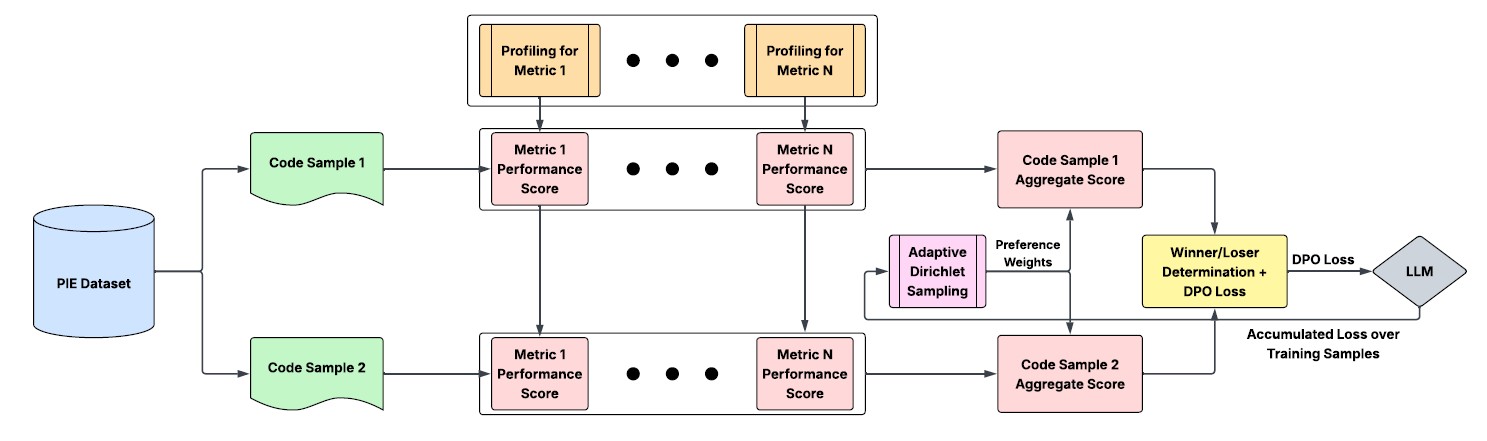
An offline preference-learning pipeline that fine-tunes a 7B-parameter code LLM with Direct Preference Optimization (DPO) to navigate sampled trade-offs across runtime, memory, CPU cycles, throughput, and energy, using an adaptive Dirichlet sampling mechanism that reweights training toward whichever objective the model is currently weakest on.
Contribution: Built by a 4-person Purdue team (Arjun Gupte, Ahmed Elmersawy, Andre Lee, Stefan Maxim) advised by Prof. James Davis. My role: implementing and stabilizing the DPO training/inference pipeline, the QLoRA fine-tuning setup for Qwen2.5-Coder-7B, the adaptive Dirichlet sampling mechanism for the Python model, the enriched 5-metric PIE data pipeline, and the inference-time evaluation benchmark (Table III results below).
- 46.7% latency, 36.0% CPU-cycle, and 36.0% energy reduction on a 7-program held-out Python inference benchmark
- 35,752 DPO preference pairs built from the enriched PIE Python split, scored across 5 system-level metrics